
Yayınlanmış makale: https://dergipark.org.tr/tr/pub/ekimad/article/1660370
1. Giriş
Finansal piyasalar ekonomik büyümeyi tasarrufların yatırımlara dönüştürülmesi, kaynakların etkin dağılımını sağlama, sermayenin marjinal verimliliğini artırma ile tasarruf oranını etkileme yollarıyla yönlendirmektedir. Finansal kurumlar, bilgi toplama ve değerlendirme fonksiyonları sayesinde yatırım projelerinin değerlendirilmesinde önemli rol oynamakta ve risk paylaşımı sağlayarak yatırımcıları daha kazançlı yatırım yapmaya teşvik etmektedir. Ayrıca, mevduat sahiplerinin likidite riskini bir havuzda toplayarak ve fonların çoğunu daha az likit ama daha verimli projelere yönlendirerek yatırımların verimliliğini artırmaktadır (Pegano, 1993:613-622).
Türkiye’de bu görevleri yerine getiren bankacılık sektörü, BIST-30 endeksinde %21.9’luk payı ile en büyük sektörel ağırlığa sahiptir. Tablo 1 bankaların Türk finans piyasalarındaki baskın rolünü açıkça göstermektedir. Özellikle BIST-30 gibi Türkiye’nin en büyük şirketlerinin yer aldığı bir endekste, bankacılık sektörünün bu denli yüksek bir ağırlığa sahip olması, sektörün Türk ekonomisindeki merkezi rolünü ve finansal sistemin bankacılık odaklı yapısını yansıtmaktadır. Bu sebeple, BIST-30 endeksinde yer alan ve sektörün önde gelen temsilcileri olan Akbank, Garanti Bankası, İş Bankası ve Yapı Kredi Bankası, yapılacak analiz için örneklem olarak seçilmiştir.
| Tablo 1. BIST30 sektörel ağırlıklar | |
| Sektör | Yüzde (%) |
| Banka | 21,9 |
| Kimya, İlaç, Petrol, Lastik ve Plastik Ürünler | 9,7 |
| Metal Eşya, Makine, Elektrikli Cihazlar ve Ulaşım Araçları | 5,6 |
| Holdingler ve Yatırım Şirketleri | 12,9 |
| Perakende Ticaret | 12,7 |
| Telekomünikasyon | 7,4 |
| Ulaştırma ve Depolama | 13,3 |
| Diğer | 16,6 |
| Kaynak: (borsaistanbul.com,2025) | |
Finansal piyasaların kritik görevleri arasında, yatırımcılar için doğru fiyat tahmini, risk yönetimi, portföy optimizasyonu ve yatırım kararlarının zamanlaması gibi öznellik içeren uygulamaların da yer alması, bu tahminlerin doğruluğunun yatırımcıların sermaye kazancı elde etme ve potansiyel kayıplardan korunma becerilerini doğrudan etkilemesiyle kendini göstermektedir. Bu zorluklar, günümüz teknolojik gelişmeleri ile aşılmaya çalışılmaktadır. İşte bu noktada, büyük veri analizi ve makine öğrenmesi teknikleri devreye girmektedir ve finansal zaman serisi tahmini risk yönetimi ve yatırım stratejilerinin belirlenmesinde kritik bir rol oynar.
Araştırmanın merkezinde yer alan derin öğrenme algoritmik ticaret, kredi riski değerlendirmesi, portföy tahsisi, varlık fiyatlaması ve türev piyasaları gibi finansal endüstri çözümlerinin gelişmesinde de rol oynamaktadır (Özbayoğlu ve diğerleri, 2020). Çalışmanın modeli olan LSTM (Long Short-Term Memory)’nin zaman serisi tahminlerindeki başarısı, elektrik fiyatı tahmini, hisse senedi fiyatı tahmini ve hava kirliliği tahmini gibi birçok alanda kanıtlanmıştır. Salgın hastalık gibi tahminlerde de ARIMA (Autoregressive Integrated Moving Average), NARNN (Nonlinear Autoregressive Neural Network) ve LSTM gibi zaman serisi tahmin yöntemleri kullanılmaktadır. Yapılan araştırmalara göre, bu çalışmalarda LSTM en doğru model olarak bulunmuştur. LSTM, özel yapısal bir RNN (Recurrent Neural Network) modeli olup, giriş, çıkış ve unutma kapılarının kontrolü ile bilgileri kurallara uygun şekilde ayıklayıp saklayabilmekte ve uzun dizilerdeki bağımlılık problemini çözebilmektedir (Wang ve diğerleri, 2020).
Genel olarak derin öğrenme modelleri, diğer istatistiksel yöntemlere göre daha üstün performans göstermektedir. Geleneksel yöntemler, yorumlanabilirlikleri ve hesaplama verimlilikleri nedeniyle tercih edilebilirler ancak finansal verilerin doğrusal olmayan ve zamana bağlı karmaşıklıklarını iletmede sıklıkla başarısız olurlar (Liu, 2025). Derin öğrenmenin en önemli avantajı, giriş verisinden otomatik olarak iyi özellikleri çıkarabilme yeteneğidir. Bu sayede öğrenme süreci kullanarak veriyi modelleyebilmektedir. Özellikle büyük veri setlerinin kullanılabilirliği, üstün performans, örtük özellik öğrenme yetenekleri ve kullanıcı dostu model geliştirme ortamları derin öğrenme modellerinin tercih edilmesindeki başlıca sebeplerdir (Sezer ve diğerleri, 2020).
Bu çalışmanın temel amacı, Türk bankacılık sektörünün önde gelen temsilcileri olan dört büyük bankanın (Akbank, Garanti Bankası, İş Bankası ve Yapı Kredi Bankası) hisse senedi fiyat hareketlerini, farklı katman sayılarına sahip LSTM modelleri kullanarak tahmin etmek ve en optimal model mimarisini belirlemektir. Araştırmanın özgünlüğü, LSTM modellerinde katman sayısının performansa etkisini sistematik bir şekilde incelemesi ve Türk bankacılık sektörü özelinde bu analizi gerçekleştirmesidir. LSTM’in tercih edilme nedeni, uzun vadeli bağımlılıkları öğrenebilme ve piyasa volatilitesindeki ani değişimleri yakalayabilme yeteneğidir. Çalışma, LSTM mimarisinin farklı katman derinliklerinin hisse senedi fiyat tahminlerindeki etkisini sistematik olarak ele alarak, tek bir ‘en iyi’ model yapılandırması yerine, veri setine özgü optimal derinlik aralığını belirlemeyi amaçlamaktadır.
Çalışmanın literatüre beklenen katkıları arasında, derin öğrenme modellerinin finansal zaman serisi tahminlerinde mimari optimizasyonuna yönelik sistematik bir yaklaşım sunması ve Türk bankacılık sektörü özelinde uygulanabilir bir tahmin modeli geliştirmesi yer almaktadır. Ayrıca, beş farklı LSTM mimarisi (bir ila beş katmanlı) ve çoklu değerlendirme metrikleri (RMSE, MAE, MAPE, R²) kullanılarak kapsamlı bir performans analizi gerçekleştirilmesi, gelecekteki çalışmalar için önemli bir referans noktası oluşturacaktır. Bu doğrultuda, bu çalışmayı şekillendiren temel araştırma sorusu, katman sayısı farklılıklarının (1’den 5’e kadar) derin öğrenme modellerinin (LSTM) Türk bankacılık sektöründeki hisse fiyatı tahmin performansı üzerinde nasıl bir etkisi olduğu şeklinde özetlenebilir.
2. Literatür Taraması
Son çalışmalar, birden fazla LSTM katmanının yer almasının modelin verilerdeki daha karmaşık desenleri öğrenmesini sağlayarak performansını artırabileceğini göstermiştir. Örneğin, araştırmalar, katmanlı bir LSTM mimarisinin hisse senedi fiyat verilerinden daha üst düzey özellikler çıkarabileceğini ve bunun da gelişmiş tahmin doğruluğuna yol açabileceğini göstermektedir (Mahboob ve diğerleri, 2023; Diqi ve diğerleri, 2024). Bu yaklaşımın etkinliği, iki katmanlı bir LSTM modelinin üç katmanlı bir modelle benzer doğruluğa ulaşabileceğini, ikincisinin ise hassasiyet ölçümleri açısından genellikle daha basit mimarilerden daha iyi performans gösterdiğini gösteren bulgularla daha da desteklenmektedir (Zhou, 2023).
Md ve diğerleri (2023), Samsung hisselerinin 23 Kasım 2016 – 23 Kasım 2021 arasındaki günlük kapanış fiyat verilerini (açılış, yüksek, düşük, kapanış, düzeltilmiş kapanış, hacim) kullanarak çok katmanlı bir LSTM modeli (toplam dört katman: üç LSTM katmanı ve bir Dense katmanı) önermiştir. Her bir LSTM katmanında 50 nöron kullanılmış, 64’lük batch boyutu, 100 günlük zaman adımı, 100 epoch ve Adam algoritmasıyla optimizasyon yapılmıştır. Model, hisse kapanış fiyatını tahmin etmek üzere tasarlanmış ve performans değerlendirmesi için R², Düzeltilmiş R², Normalleştirilmiş RMSE ile MAPE gibi metriklerden yararlanılmıştır. Çalışmada, eğitim verisinde R² değerinin 0,959; test verisinde ise 0,981 olduğu, ayrıca MAPE oranının test setinde %2,18’e düştüğü rapor edilmiştir. Hiperparametre seçimi, yazarların deneysel değerlendirmeleri sonucunda belirlenmiştir.
Bhandari ve diğerleri (2022), 2006-2021 dönemine ait S&P 500 verilerini kullanarak temel (örneğin açılış-kapanış), makroekonomik (Volatilite Endeksi, İşsizlik Oranı, faiz oranı, Tüketici Güveni, Dolar Endeksi) ve teknik indikatör (MACD, ATR, RSI) değişkenlerinden oluşturulan bir veri seti üzerinde tek katmanlı ve çok katmanlı LSTM modellerini incelemişlerdir. Tek katmanlı yapı için 10, 30, 50, 100, 150 ve 200 nöronlu, çok katmanlı yapı için ise (20,10), (50,20), (100,50), (150,100) ve benzeri katman kombinasyonları denenmiş; her bir mimaride optimizasyon yöntemi (Adam, Adagrad, Nadam), öğrenme oranı (0.1, 0.01, 0.001) ve batch boyutu (4, 8, 16) sistematik biçimde farklı kombinasyonlar üzerinden taranarak seçilmiştir. Modele ait epoch sayısı doğrulama kayıpları belirli bir seyir gösterene kadar artırılmış, ayrıca bazı denemelerde dropout oranı (örneğin %10) kullanılmış ancak performansa anlamlı katkı sağlamamıştır. Ertesi günün kapanış fiyatını hedef alan tahmin işlemleri için RMSE, MAPE ve korelasyon (R) metrikleri kullanılmış; özellikle tek katmanlı ve 150 nöronlu LSTM modelinin düşük RMSE (40), düşük MAPE (0.8) ve yüksek R (0.997) değerleriyle en başarılı sonuçları verdiği rapor edilmiştir.
Zaheer ve diğerleri (2023), Shanghai Karma Index verilerini 3 Temmuz 1997–24 Ocak 2022 aralığında günlük olarak (açılış, yüksek, düşük, kapanış, düzeltilmiş kapanış, hacim sütunlarını içerecek şekilde) kullanarak hisse senedi fiyat tahmini gerçekleştirmiştir. Çalışmada, CNN-LSTM-RNN temelli bir yöntem önerilmiş ve özellikle tek katmanlı bir RNN (64 nöron), tek katmanlı bir LSTM (64 nöron) ve 32 filtreli bir 1D-CNN kullanılmıştır. Aktivasyon fonksiyonu olarak tanh, optimizasyon için Adam, kayıp fonksiyonu için MAE seçilmiş; ayrıca 10 zaman adımı, 64’lük batch boyutu ve 100 epoch üzerinden deneyler yürütülmüştür. Hiperparametre seçimi sabit değerlere dayalı deneysel bir yaklaşımla belirlenmiş olup, model iki temel hisse parametresi (close ve high) için bir günlük ileriye dönük tahmin yapmıştır. Performans ölçümünde MAE, RMSE ve R² metrikleri kullanılmış ve elde edilen sonuçlara göre tek katmanlı RNN modeli 0.986 R² ile diğer yaklaşımlardan daha başarılı bulunmuştur.
Sunny ve diğerleri (2020), Google hisselerine ait 19/08/2004-04/10/2019 aralığındaki açılış, yüksek, düşük ve kapanış fiyatlarını içeren verileri kullanarak LSTM ve Bi-LSTM tabanlı bir tahmin modeli önermiştir. Söz konusu çalışmada veri ön işleme sonrası verilerin yüzde 88’i eğitim, geri kalanı test için ayrılmış; farklı katman yapılandırmaları (örneğin 2 veya 4 gizli katman) ve farklı nöron sayıları (64 veya 128) denenmiştir. Aktivasyon fonksiyonu olarak genellikle ReLU kullanılırken, epoch sayısı 10’dan 250’ye kadar değiştirilmiştir. Optimizasyon algoritması ve batch boyutu ile ilgili bilgiler net olarak belirtilmemekle birlikte, hiperparametre seçimi deneysel olarak yapılmıştır. Her iki model de gelecekteki hisse senedi fiyatlarını tahmin etmeyi amaçlamış; performans değerlendirmesinde RMSE metriği kullanılmıştır. Çalışmanın sonucunda, Bi-LSTM’in LSTM’e kıyasla daha düşük RMSE verdiği ve bu nedenle daha başarılı bir tahmin performansı gösterdiği belirtilmiştir.
Behura ve diğerleri (2023), TATA Consumer hissesine ait 1 Ocak 2018–31 Aralık 2022 dönemini kapsayan ve yalnızca kapanış fiyatları ile tarih sütunlarını içeren bir veri seti kullanarak LSTM tabanlı bir tahmin çalışması gerçekleştirmiştir. Çalışmada, her bir LSTM katmanında 10 nöron bulunacak şekilde, iki, üç ve dört gizli katmana sahip farklı modeller denenmiş; gizli katmanlarda “relu” aktivasyon fonksiyonu uygulanmıştır. Optimizasyon sürecinde “adam” kullanılmış, eğitim 10 epoch ile sınırlandırılmıştır; ancak batch büyüklüğü detaylı olarak belirtilmemiştir. Temel hedef, önce geçmiş 10 güne dayanarak bir sonraki günün kapanış fiyatını, daha sonra ise yine geçmiş 10 günden sonraki 5 günün fiyatlarını çok adımlı (multi-step) olarak öngörmektir. Performans, doğruluk (accuracy) metriğiyle değerlendirilmiş ve üç katmanlı LSTM mimarisinin %99,42’lik eğitim doğruluğuna ulaştığı, test verisinde ise model doğruluğunun %98,76 ile %96,71 arasında değiştiği rapor edilmiştir. Hiperparametre optimizasyonu yalnızca farklı katman sayıları üzerinde sınırlı düzeyde gerçekleştirilmiştir.
Konur ve diğerleri (2024), Borsa İstanbul (BIST100) endeksinde yer alan ve piyasa değeri yüksek ilk beş şirketin (Koç Holding, Türk Hava Yolları, Ford Otosan, Türkiye Petrol Rafinerileri, İş Bankası) Şubat 2020-Aralık 2023 arasındaki günlük kapanış fiyatlarını içeren veri setini kullanarak LSTM tabanlı çeşitli derin öğrenme modelleri geliştirmiştir. Çalışmada; tek katmanlı, üç katmanlı ve çift yönlü (BiLSTM) olmak üzere üç farklı LSTM modeli ile bir hibrit CNN-LSTM modeli karşılaştırılmış; sırasıyla 64 ile 128 nöronlu katmanlar, Adam optimize edicisi (öğrenme oranı 0,001), 100 epoch ve 8’lik batch boyutu kullanılmıştır. Ayrıca aktivasyon fonksiyonu olarak ReLU ve Tanh tercih edilmiştir. Modellerin temel amacı günlük kapanış fiyatlarını tahmin etmek olup performans değerlendirmesinde MSE, MAE, RMSE, MAPE, EVS, R², MDA ve MSLE metrikleri kullanılmıştır. Sonuçlar, tek katmanlı LSTM modelinin düşük MSE ve yüksek R² değerleriyle en iyi tahmini sağladığını göstermiştir. Hiperparametre seçimi, deneysel denemeler ve önceki çalışmalar ışığında belirlenmiştir.
Bu çalışma ise bankacılık sektörü özelinde farklı katmanlara sahip LSTM modellerinin etkilerini ortaya koyarak literatürdeki diğer çalışmalardan farklılaşmaktadır.
3. Metodoloji
Bu çalışmada, Borsa İstanbul’da işlem gören dört büyük bankanın (Akbank, Garanti Bankası, İş Bankası ve Yapı Kredi Bankası) hisse senedi fiyat hareketlerinin tahmini için derin öğrenme tabanlı bir metodoloji uygulanmıştır. Araştırmada, farklı katman sayılarına sahip (1-5 katman) Uzun-Kısa Süreli Bellek (LSTM) ağları kullanılmıştır.
3.1. Veri Seti ve Ön İşleme
Çalışmada kullanılan veriler 2007-01-01 ile 2022-01-01 tarihleri arası için her bir banka adına 3764 (ISCTR için 2007-12-31 tarihi itibariyle 3306 gün) günlük setler oluşturmuştur. Python 3.13 programı ile yfinance kütüphanesi kullanılarak elde edilen setler açılış, yüksek, düşük, kapanış ve işlem hacmi değişkenlerini içermektedir.
Şekil 1. Yıllar içerisinde hisse senetleri kapanış fiyatı trendleri
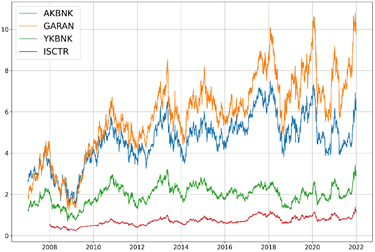
Veri setinin eğitim, doğrulama ve test setlerine ayrılması aşamasında, zaman serisi verilerinin kronolojik yapısı korunmuştur. Bu doğrultuda, veri setinin ilk %70’lik kısmı eğitim seti, sonraki %15’lik kısmı doğrulama seti ve son %15’lik kısmı test seti olarak belirlenmiştir (Htay ve diğerleri, 2025; Boukhers ve diğerleri, 2022; Yenidoğan ve diğerleri, 2018). Veri kümelerinin eğitim, doğrulama ve test alt kümelerine bölünmesi, sağlam model değerlendirmesi sağlamayı ve aşırı uyumu önlemeyi amaçlayan makine öğrenmesinde temel bir uygulamadır. Eğitim kümesi model parametrelerine uymak için kullanılırken, doğrulama kümesi hiper parametre ayarlama ve model seçimi için kullanılır ve görülmemiş verilerde model performansının tarafsız bir şekilde değerlendirilmesine olanak tanır (Figueiredo ve Mendes, 2024). Eğitim ve doğrulama kümelerinden farklı olan test kümesi, son modelin genelleme yeteneklerini değerlendirmeye yarar ve modelin tamamen yeni verilerde iyi performans göstermesini sağlar (Tampu ve diğerleri, 2022).
Veri ölçekleme aşamasında, her bir hisse senedi için ayrı MinMax ölçekleme uygulanmıştır. MinMax ölçekleme, verileri [0,1] aralığına dönüştürerek, farklı ölçeklerdeki değişkenlerin model eğitiminde eşit ağırlığa sahip olmasını sağlamaktadır. MinMax normalizasyonunun, özellikle bilinen sınırlara sahip veri kümeleriyle uğraşırken z-puanı normalizasyonu gibi diğer yöntemlere kıyasla daha iyi sonuçlar verdiği bildirilmiştir (Prasetyowati ve diğerleri, 2022).
Zaman serisi verilerinin LSTM modeline uygun hale getirilmesi için kayan pencere yaklaşımı kullanılmıştır. Bu yaklaşımda, literatürde sıkça kullanılan 60 gün pencere boyutu sekanslar oluşturulmuştur. Bu yapı, modelin geçmiş 60 günlük veriyi kullanarak bir sonraki günün kapanış fiyatını tahmin etmesini sağlamaktadır. Kayan pencere tekniği, hisse senedi fiyatlarının dinamik yapısına uyum sağlayarak sürekli model eğitimi ve doğrulamasına olanak tanır (Cheng, 2024).
3.2. Model Mimarisi
Uzun-Kısa dönem bellek (LSTM), özellikle zaman serisi verilerini ve uzun süreli bağımlılıkları modelleme amacıyla geliştirilmiş bir tür yinelemeli sinir ağı mimarisidir. Klasik RNN’lerin uzun sekanslarda karşılaştığı gradyan sorunlarını hafifletmek üzere tasarlanan LSTM (Okut, 2021), her bir bellek bloğunda bulunan giriş, çıkış ve unutma kapıları sayesinde bilginin akışını kontrollü biçimde düzenler. LSTM modeli Tablo 2’de verilmiştir.
Tablo 2. LSTM matematiksel modeli
| fₜ = σ(Wf,x · xₜ + Wf,h · hₜ₋₁ + bf) |
| iₜ = σ(Wi,x · xₜ + Wi,h · hₜ₋₁ + bi) |
| c̃ₜ = tanh(Wc,x · xₜ + Wc,h · hₜ₋₁ + bc) |
| cₜ = fₜ ⊙ cₜ₋₁ + iₜ ⊙ c̃ₜ |
| oₜ = σ(Wo,x · xₜ + Wo,h · hₜ₋₁ + bo) |
| hₜ = oₜ ⊙ tanh(cₜ) |
Kaynak: Fischer ve Kraus (2018)
Verilen LSTM denkleminde xt, zaman adımındaki giriş verisini ifade ederken, ht−1 bir önceki zaman adımındaki gizli durumdur; bu iki girdi, sırasıyla unutma, giriş, aday hücre durumu ve çıkış kapılarının hesaplamalarında kullanılır. Unutma kapısı için Wf,x ve Wf,h ağırlık matrisleri, xt ve ht−1 ’den gelen bilgilerin kapıya etkisini belirlerken, bf sapma terimi eklenerek ft=σ(Wf,x⋅xt+Wf,h⋅ht−1+bf) denklemiyle, geçmiş hücre durumunun ne kadarının korunacağı 0 ile 1 arasında bir değerle belirlenir. Denklemdeki σ işareti sigmoid fonksiyonunu temsil eder. Sigmoid fonksiyonu, derin öğrenme modellerinde en çok kullanılan ve klasik bir doğrusal olmayan (non-lineer) fonksiyondur (Kılınçarslan ve diğerleri, 2021).
Benzer şekilde, giriş kapısında Wi,x ve Wi,h ağırlıkları ile bi sapması kullanılarak it=σ(Wi,x⋅xt+Wi,h⋅ht−1+bi) hesaplanır; bu kapı, yeni bilginin ne ölçüde hücre durumuna ekleneceğini düzenler. Aday hücre durumu, Wc,x ve Wc,h ağırlıkları ile bc sapması kullanılarak ve tanh aktivasyon fonksiyonunun uygulanmasıyla c̃ₜ=tanh(Wc,x⋅xt+Wc,h⋅ht−1+bc) olarak hesaplanır; bu bilgi, güncellenmiş hücre durumunun oluşturulmasında kullanılır. Tanh fonksiyonu sayesinde, hücre durumu içerisinde bulunan değerler tutarlı bir şekilde -1 ile 1 arasında değişen makul bir aralıkla sınırlandırılır (Gambhir ve diğerleri, 2023). Hücre durumu ct ise, ft ile önceki hücre durumu ct−1’nin eleman bazında çarpımı ile it ve c̃ₜ’nin eleman bazında çarpımının toplamı şeklinde güncellenir: ct=ft⊙ct−1+it⊙ c̃ₜ burada ⊙ işareti Hadamard çarpımını temsil eder. Hadamard çarpımı, bilimsel hesaplama ve veri analizi için tensör tabanlı algoritmalarda temel bir işlemdir (Sun ve diğerleri, 2024).
Son olarak, çıkış kapısı Wo,x ve Wo,h ağırlıkları ile bo sapması kullanılarak ot=σ(Wo,x⋅xt+Wo,h⋅ht−1+bo) hesaplanır ve nihai gizli durum ht, çıkış kapısı ot ile güncellenmiş hücre durumunun tanh fonksiyonundan geçirilmiş halinin eleman bazında çarpımı olarak elde edilir: ht=ot⊙tanh(ct). Bu denklemlerde yer alan tüm parametreler, öğrenme sürecinde optimize edilir ve modelin zaman serisi verilerindeki uzun vadeli bağımlılıkları etkili şekilde yakalamasını sağlar (Fischer ve Kraus, 2018).
3.3. Modellerin Eğitim Parametreleri
LSTM’ler için öğrenme oranları, gizli birim sayısı ve giriş uzunluğu dahil olmak üzere birçok hiperparametre mevcuttur. Hiperparametreler, modelin nasıl öğrendiğini düzenlemek için özel olarak tanımlanmış parametrelerdir (Ismanto ve Effendi, 2024).
Bu çalışmada, LSTM modellerine ait hiperparametreler (ör. öğrenme oranı, batch size, katman ve nöron sayıları, dropout oranları vb.) öncelikle literatür taraması yoluyla belirlenen bir parametre uzayı üzerinden tanımlanmış; sonrasında ise deneysel bir arayış stratejisi uygulanmıştır. Benzer finansal zaman serisi tahmin çalışmalarında önerilen 0.001 ve 0.0001 gibi öğrenme oranları, 32-128 aralığındaki batch size değerleri ve 1’den 5’e kadar katman sayısı denemeleri, model performansını gözeterek değerlendirilmiştir. Böylece, seçilen parametre kombinasyonlarının her birinde eğitim ve doğrulama hataları izlenmiş, aşırı öğrenme (overfitting) riskine karşı erken durdurma tekniğinden (early stopping) yararlanılmıştır. Bu yaklaşım, literatürdeki yaygın yöntemlerle (ör. Grid Search, Random Search) benzer bir mantık izlemekle birlikte, daha pragmatik bir deneysel çerçevede ilerlemiştir.
Öncelikle nöron sayısı, öğrenme oranı ve batch size değerleri, önceki araştırmalarda (özellikle finansal veri setleri için) elde edilen başarılı sonuçlar temel alınarak belirli bir aralıkta (örneğin 128, 64, 32 gibi) sınırlandırılmıştır (Yurtsever, 2021; Xu ve Yoneda, 2019; Utomo ve diğerleri, 2024; Safa ve Oetama, 2024). Literatüre dayalı bu başlangıç aralığı, her katmanda giderek azalan nöron sayıları ve sabit dropout oranı (0.2) üzerinden sınırlandırılmıştır. Daha sonra, deneme yanılma (trial-and-error) tekniğiyle bu parametre kombinasyonları sırayla eğitilerek, hem doğrulama kaybı hem de genel tahmin metrikleri (RMSE, MAPE, R²) üzerinden incelenmiştir. Elde edilen sonuçlara göre, model karmaşıklığı (katman sayısı ve nöron dağılımı) belirli bir seviyeyi aştığında performans kaybı gözlendiği için, en yüksek doğruluk elde eden katman/nöron yapılandırması seçilmiştir. Bu süreçte hem modelin eğitim süresi hem de aşırı öğrenme belirtileri (val_loss sapmaları) gözetilerek, nihai hiperparametre değerleri pratik ve akademik literatürle uyumlu bir denge yakalayacak biçimde optimize edilmiştir.
Tablo 3. Modelde kullanılan hiperparametreler
| Katman Sayısı | Nöron Sayısı | Dropout Oranları | Diğer | ||
| 1 | 128 | 0,2 | Batch Size | 64 | |
| 2 | 128 64 | 0,2 0,2 | Epok Sayısı | 300 | |
| 3 | 128 64 32 | 0,2 0,2 0,2 | Öğrenme Oranı | 0,001 | |
| 4 | 128 64 32 16 | 0,2 0,2 0,2 0,2 | Pencere Boyutu | 60 | |
| 5 | 128 64 32 16 8 | 0,2 0,2 0,2 0,2 0,2 | Erken Durdurma | Aktif | |
Erken durdurma için patience değeri 15 olarak belirlenmiştir. Bu teknik, aşırı uyumu azaltarak model performansını iyileştirdiği gösterilen hisse senedi fiyat tahmini de dahil olmak üzere çeşitli LSTM uygulamalarında yaygın olarak benimsenmiştir (Zhang ve diğerleri, 2021). Batch size değeri, modelin her iterasyonda işlediği örnek sayısını ifade ederken, epoch sayısı tüm eğitim verisinin modele kaç kez sunulacağını belirler. Öğrenme hızı, optimizasyon algoritması olan Adam’ın parametre güncellemelerinin büyüklüğünü kontrol etmekte ve dolayısıyla modelin yakınsamasında kritik rol oynamaktadır. Daha düşük bir öğrenme oranı genellikle daha yüksek doğruluğa yol açar; bu durum çalışmalarla kanıtlanmıştır; daha yüksek oranlar ise daha düşük performansa yol açabilir (Jepkoech ve diğerleri, 2021).
LSTM mimari parametreleri ise modelin derinlik ve karmaşıklığını belirleyen önemli yapı taşları olarak öne çıkmaktadır. Bu çalışmada, 1’den 5’e kadar farklı katman derinliklerine sahip LSTM modelleri, her biri için belirlenen nöron sayıları (units) ve modelin eğitim verisini çok iyi öğrenerek yeni verilerde kötü performans göstermesini yani aşırı öğrenmeyi engellemeye çalışan (Hillier ve diğerleri, 2024) dropout oranları kullanılarak yapılandırılmıştır. Örneğin, tek katmanlı LSTM modelinde 128 nöron kullanılırken, daha derin modellere geçildikçe her katmanda nöron sayısı kademeli olarak azaltılarak 128, 64, 32, 16 ve 8 gibi değerler tercih edilmiştir. Dropout oranları, her katmanda belirli bir oranda (0.2) uygulanmaktadır. Bu parametrik yapılandırma, farklı derinliklerdeki modellerin performansını karşılaştırmaya ve veri setine en uygun model mimarisini belirlemeye yönelik sistematik bir yaklaşım sunmaktadır.
4. Bulgular
Bu çalışmada, farklı sayılarda LSTM katmanı kullanılarak dört farklı banka hissesinin (AKBNK, GARAN, ISCTR, YKBNK) zaman serisi verileri üzerinde tahmin modelleri oluşturulmuştur. Modellerin performansı, RMSE (Root Mean Squared Error), MAE (Mean Absolute Error), MAPE (Mean Absolute Percentage Error) ve R² (R-Kare) metrikleriyle değerlendirilmiştir (Şimşek, 2024;Yuan ve diğerleri, 2025; Mutinda ve Geletu,2025). Değerlendirmede, hem tahmin hatasının niceliğini hem de modelin varyansı açıklama gücünü yansıtan bu metrikler, hangi katman sayısının daha iyi sonuçlar verdiğini açıkça ortaya koymuştur.
Tablo 4. Değerlendirme metrikleri
| RMSE | Tahmin edilen ile gerçek değer arasındaki farkların karelerinin ortalamasının karekökünü ifade eder ve bu değer küçüldükçe tahmin performansı artar. |
| MAE | Tahmin edilen ile gerçek değer arasındaki ortalama mutlak hatadır ve değeri küçüldükçe modelin tahmin doğruluğu artar. |
| MAPE | Tahmin edilen ve gerçek değer arasındaki mutlak yüzde farklarının ortalaması olup hatayı yüzde cinsinden ifade ederek model farklılıklarının açıklanmasını ve karşılaştırılmasını kolaylaştırır. |
| R2 | Değeri genellikle 0 ile 1 arasında olup, regresyon modellerinin uyum başarısını değerlendirir.1’e yaklaştıkça modelin uyumu o kadar iyi demektir. |
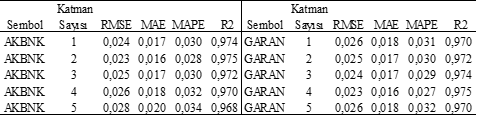
AKBNK hisse senedi verisi üzerinde yapılan LSTM analizleri sonucunda en yüksek performans 2 katmanlı modelde elde edilmiştir. Bu modelin R² değeri %97,5 ile oldukça güçlüdür ve RMSE (0,023), MAE (0,016) ve MAPE (0,028) değerleri de düşük düzeydedir. Tek katmanlı model de benzer bir başarı göstermiştir, fakat katman sayısı üç ve üzerine çıkarıldığında model performansında belirgin düşüş gözlenmiştir. Bu durum, AKBNK hissesinin veri yapısının orta düzey karmaşıklıkta olduğunu ve aşırı derinleştirilen modellerin overfitting’e neden olduğunu göstermektedir. Sonuç olarak, AKBNK için en uygun mimarinin iki katmanlı LSTM olduğu anlaşılmaktadır; daha karmaşık modeller gereksiz komplekslik yaratarak genelleştirme performansını azaltmaktadır.
GARAN hissesi için yapılan analizlerde en iyi performans 3 ve 4 katmanlı modellerle sağlanmıştır (R² sırasıyla %97,4 ve %97,5). Bu modellerin RMSE (0,024-0,023), MAE (0,017-0,016) ve MAPE (0,029-0,027) değerleri oldukça düşük, tahmin gücü yüksektir. Katman sayısı arttırıldığında (özellikle 5 katman) model karmaşıklığının artmasıyla performans düşüşü gözlenmeye başlanmıştır. Buna karşın GARAN hissesi için tek katmanlı model de tatmin edici sonuçlar sağlamıştır, ancak daha derin mimariler sınırlı da olsa bir gelişme getirmiştir. Genel olarak GARAN hisse senedinin fiyat hareketlerinin tahmininde orta derinlikteki (3-4 katman) modellerin tercih edilmesi önerilebilir.
Tablo 5. Akbank ve Garanti Bankası Metrikleri
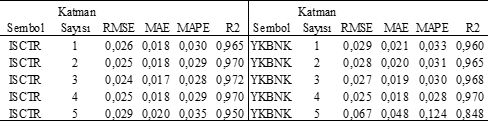
ISCTR sembolü üzerinde yapılan analizde, optimal sonuç üç katmanlı mimaride elde edilmiştir (R² = 0,972). Üç katmanlı modelin düşük RMSE (0,024), MAE (0,017) ve MAPE (0,028) değerleri, tahminlerin yüksek doğruluğunu göstermektedir. Katman sayısı arttıkça, özellikle 5 katmanlı mimaride belirgin performans düşüşü görülmektedir (R² = 0,950). Bu durum ISCTR hissesi için aşırı derin mimarilerin uygun olmadığını ve yüksek karmaşıklığın aşırı öğrenme riskini artırdığını işaret etmektedir. ISCTR hisse verileri için en dengeli ve etkili performans, orta düzeyde (2-3 katmanlı) LSTM modelleri ile sağlanmaktadır.
YKBNK hissesi, analiz edilen hisse senetleri arasında en farklı davranış sergileyen sembol olarak öne çıkmaktadır. En başarılı sonuç dört katmanlı LSTM modeli ile elde edilmiştir (R²=0,970; RMSE=0,025; MAE=0,018; MAPE=0,028). Bununla birlikte, 5 katmanlı mimaride ciddi bir performans düşüşü yaşanmıştır (R²=0,848 ve MAPE=0,124). Bu ani ve yüksek hata oranı, modelin aşırı karmaşıklaşmasının veriler üzerinde net bir aşırı öğrenme sorununa yol açtığını göstermektedir. Tek ve iki katmanlı modeller ise daha ılımlı ancak daha düşük performans sergilemiştir. Bu nedenle YKBNK için en ideal model derinlik seviyesi, 3 veya 4 katman olarak belirlenebilir. Daha fazla derinleşmek, model performansını ciddi şekilde olumsuz etkilemektedir.
Tablo 6. İşbankası ve Yapı Kredi Bankası Metrikleri
5. Sonuç
Bu çalışma, Türk bankacılık sektöründe yer alan dört büyük bankanın (Akbank, Garanti Bankası, İş Bankası ve Yapı Kredi Bankası) hisse senedi fiyatlarını LSTM tabanlı farklı katman derinliklerine sahip modellerle tahmin etmeyi amaçlamıştır. Elde edilen bulgular, orta derinlikteki (2-4 katman) modellerin tahmin performansının genellikle tek katmanlı veya çok katmanlı (5 ve üzeri) modellerden daha iyi olduğunu göstermiştir. Akbank için en iyi tahmin performansı iki katmanlı LSTM ile elde edilirken, Garanti Bankası ve İş Bankası için üç veya dört katmanlı modellerin benzer yüksek performans sunduğu gözlenmiştir. Yapı Kredi Bankası’nda dört katmanlı model öne çıkmış; beş katmanda ise belirgin bir aşırı öğrenme (overfitting) etkisi nedeniyle performans kaybı yaşanmıştır. Bu sonuçlar, LSTM katman derinliğinin veri setinin özelliklerine bağlı bir şekilde titizlikle belirlenmesi gerektiğinin altını çizmektedir. Bu sonuçlar, Bhandari ve diğerleri (2022) ile Zaheer ve diğerleri (2023)’nin katman sayısındaki artışın model performansını her zaman iyileştirmediği ve bazı durumlarda karmaşıklığın aşırı öğrenmeye yol açtığı yönündeki bulgularıyla da uyumludur. Dolayısıyla mevcut çalışmanın sonuçları, literatürdeki benzer araştırmaların genel bulgularını destekler niteliktedir.
Çalışmada kullanılan veri ön işleme ve modelleme yaklaşımının (zaman serisi verilerini eğitim-doğrulama-test olarak %70-%15-%15 oranında ayırma, MinMax ölçekleme, 60 günlük kayan pencere vb.) finansal tahmin modelleri açısından geçerli ve etkili olduğu söylenebilir. Özellikle finansal piyasaların yapısal olarak volatil ve ani değişimlere açık olması, LSTM gibi uzun süreli bağımlılıkları yakalayabilen modelleri daha avantajlı hale getirmektedir. Bununla birlikte, sonuçlar göstermektedir ki derin öğrenme tekniği kullanmak, her zaman katman sayısını artırarak başarıya ulaşmak anlamına gelmemektedir; tam aksine, katman sayısı arttıkça modelin aşırı karmaşıklaşması ve veriye aşırı uyum göstermesi olasıdır.
Elde edilen bulgular ayrıca, farklı banka hisseleri için en iyi sonuç veren katman sayısının farklılaşabileceğini ortaya koymaktadır. Bu durum, ilgili bankanın hisse senedi fiyat dinamiklerinin veya piyasa koşullarındaki oynaklıkların kendine özgü desenlere sahip olabileceğini yansıtmaktadır. Dolayısıyla, tek bir evrensel “en iyi katman derinliği” yerine, her veri setinin özelliklerini ve modelin nasıl genelleşebildiğini dikkate alan bir yaklaşım benimsenmelidir. Bu kapsamda, model seçimi ve mimari yapılandırma sürecinde, önceki çalışmalardan ve mevcut literatürden edinilen bilgiler, deneysel sonuçlarla harmanlanarak en uygun konfigürasyon belirlenmelidir.
Araştırmanın hem akademik hem de sektörel uygulamalara önemli katkıları bulunmaktadır. Akademik alanda, katman derinliğinin finansal tahmin performansına etkisini Türk bankacılık sektörü verileriyle sistematik biçimde ele alması, literatürdeki benzer çalışmalar için de yol gösterici olabilir. Sektörel açıdan bakıldığında ise, bankaların hisselerine yatırım yapan fon yöneticileri, bireysel yatırımcılar ya da risk yöneticileri; optimal katman derinliğine sahip LSTM modelleri sayesinde daha doğru fiyat tahmini ve dolayısıyla daha isabetli kararlar verebilirler.
Gelecek çalışmalar, bu bulguları daha da çeşitlendirip derinleştirmek amacıyla farklı mimariler (örneğin CNN-LSTM, GRU, Transformer vb.) ile katman sayısı ve nöron dağılımı kombinasyonlarını test edebilir. Ayrıca, veriye eklenebilecek makroekonomik indikatörler, metin madenciliğinden elde edilen duyarlılık analizleri (sentiment) veya sektörel haber akışı gibi ek faktörler de modelin öngörü gücünü arttırabilir. Böylelikle, finansal zaman serisi tahmininde derin öğrenmenin farklı boyutları daha kapsamlı şekilde araştırılabilir ve özellikle bankacılık sektörüne özgü dinamiklerin model performansı üzerindeki etkisi daha net biçimde anlaşılabilir.